Introduction to Metrics Framework Concepts
The objective of using Transform's Metrics Framework is to define and manage the logic used to build a company's metrics. The Metrics Framework is an opinionated set of abstractions that enable the data consumer to retrieve metric datasets efficiently from a data warehouse. There are a few key principles:
- Flexible, but complete - Define logic in abstractions that are flexible enough to construct any metric on any data model
- Don't Repeat Yourself (DRY)- Whenever possible enable the definition of metrics
- Simple with progressive complexity - Rely on known concepts and structures in data modeling to ensure that the Metrics Framework is approachable. Create escape hatches that enable folks to pursue more advanced and unsupported features.
- Performant and Efficient- Enable performance optimizations of centralized data engineering while enabling distributed definition and ownership of logic.
What is a metric in the context of Transform?#
A metric is a quantitative indicator of the performance of a system such as a product or business.
Technically, a metric can be thought of as a function that takes data and dimensions as input and creates a set of numerical values as output. Those numerical values can be used in a variety of downstream applications. A metric is constructed with the context of a dimensional granularity. Dimensions can be several different types that have different properties such as time or categorical. Similarly, identifiers can be used as a dimension (i.e. revenue by user) but they have the added benefit of being used as join keys that allow us to pull in context from other datasets.
Example Data Model#
The example data schema below shows a number of different types of data sources:
transactions is a production DB export that has been cleaned up and organized for analytical consumption
visits is a raw event log
stores is a cleaned up and fully normalized dimensional table from a daily production database export
products is a dimensional table that came from an external source such as a wholesale vendor of the good this store sells.
customers is a partially denormalized table in this case with a column derived from the transactions table through some upstream process
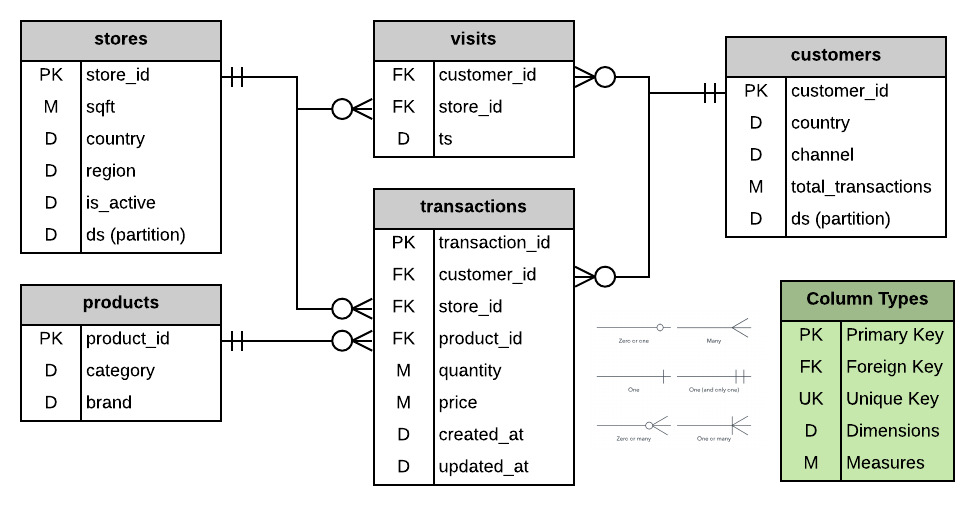
In order to make this more concrete let's consider the metric revenue defined (without any dimensions) as the SQL expression select sum(price * quantity) as revenue from transactions
Metric Queries#
Dimensions, in this case, can come from the transactions table as a granularity of time such as date_trunc(created_at, 'day') or from other tables such as the product table where we could get the product_category. We could calculate the metric aggregated to both dimensions in the following way:
select date_trunc(transactions.created_at, 'day') as day , products.category as product_category , sum(transactions.price * transactions.quantity) as revenuefrom transactionsjoin productson transactions.product_id = products.product_idgroup by 1, 2The metric above is revenue but enriched with the context of a time and categorical dimension.
It's likely that the data models you have seen are more complicated than the one above. There are many challenges associated with building metrics in this way across a variety of different data models and the choice of the abstractions in the Metrics Framework are geared towards enabling a wide variety of data models and types of data.
Metrics Framework Overview
The Metric Framework aims to capture the metric logic in a way such that it can construct the appropriate queries to build metrics to the many granularities that may be useful for various business applications.
There are two critical objects to the metric definition in the Metrics Framework: the [Data Source] and Metric. Understanding these will allow you to configure metrics and dimensions in a way that will minimize redundancy while maximizing the potential of the Metrics Framework on top of your data.
Metrics are built on top of Data Sources and in many cases (but not always, see FAQ) are defined as a function of Measures. Data Sources together produce a data model that can then be compiled and consumed through Transform's various APIs which then constructs SQL on top of the various data sources to resolve metrics at various granularities.
Data Sources (docs)#
The input to the Metrics Framework is a data source. The data source is defined as a Table or a SQL Query. When possible a table is a more efficient input into the Metrics Framework because it puts more of the logic into the abstractions of the Metrics Framework which allows for Transform to perform more optimizations on the backend.
The columns in a data source can be used to construct three objects by whatever SQL logic a user wishes to express. The three objects are Identifiers, Measures, & Dimensions.
Identifiers: Act as the join keys between tables and using their types (primary, foreign, or unique) the Metrics Framework constructs the appropriate joins with other tables. They also have all the properties of a dimension in that they can act as a granularity for aggregation.
Measures: Measures are aggregatable expressions written from the various columns of the underlying table or query. The definition of a measure includes an aggregation type that is then used to construct metrics.
Dimensions: Dimensions are non-aggregatable expressions that are used to define the level of aggregation that a Metrics Framework user would like a metric to be aggregated to.
As an example, the transactions table might be used as a data source in the Metrics Framework as follows:
data_source: name: transactions description: A record for every transaction that takes place. Carts are considered multiple transactions for each SKU. owners: support@transform.co sql_table: schema.transactions
# --- IDENTIFIERS --- identifiers: - name: transaction_id type: primary - name: customer_id type: foreign - name: store_id type: foreign - name: product_id type: foreign
# --- MEASURES --- measures: - name: revenue description: expr: price * quantity agg: sum - name: quantity description: Quantity of products sold expr: quantity agg: sum - name: active_customers description: A count of distinct customers completing transactions expr: customer_id agg: count_distinct
# --- DIMENSIONS --- dimensions: - name: ds type: time expr: date_trunc('day', ts) type_params: is_primary: true time_format: YYYY-MM-DD time_granularity: day - name: is_bulk_transaction type: categorical expr: case when quantity > 10 then true else false endSimilarly we could then create a products data source as follows:
data_source: name: products description: A record for every product available through our retail stores. owners: support@transform.co sql_table: schema.products
# --- IDENTIFIERS --- identifiers: - name: product_id type: primary
# --- DIMENSIONS --- dimensions: - name: category type: categorical - name: brand type: categorical - name: is_perishable type: categorical expr: | category in ("vegetables", "fruits", "dairy", "deli")We can now take metrics constructed off of measures in the transactions data source and aggregate them to the granularity of the dimensions in the products data source. As an example, we could use these two data sources to construct the query shown above where we calculate revenue by product__category and day.
Key Concepts#
A few key concepts to think about when modeling data:
Aggregation of Measures: The Metrics Framework can aggregate measures to the granularity of any of the identifiers in the table. If aggregated to the granularity of one of those identifiers, then we can pull in the various dimensions that apply to that identifier adding context to the data.
Dimensions as properties of Primary Identifiers: Dimensions cannot be aggregated and so they are then considered to be a property of the primary or unique identifiers of the table. In the table above, is_bulk_transaction is considered to be an attribute of a transaction_id. This dimension is then useable in the Metrics Framework by any metric that can be aggregated to the transaction granularity.
Joins are created by Identifier Types: When creating a data source it's important to think about which other data sources will be able to use the data source to combine metrics and dimensions. There are three key types in the Metrics Framework, primary, unique and foreign, and then 9 potential join pairs. The Metrics Framework avoids fan-out and chasm joins by avoiding foreign to foreign, primary to foreign, and unique to foreign joins.
Metrics (docs)#
A metric can be thought of as a function on top of the various data sources. In the example above, we have created a revenue measure. The simplest type of metric is a measure_proxy which means that the metric is just a measure. One way to define this metric is in the data source as follows:
measures: - name: revenue description: expr: price * quantity agg: sum create_metric: trueOr the metric can be defined explicitly with a more complete set of configuration features:
metric: name: revenue description: Revenue is price x quantity for every product sold and recorded in the transactions table. type: measure_proxy type_params: measures: revenueBy defining the metric in this way, the Metrics Framework can then dynamically traverse the various data models constructing SQL queries(like the one shown in the section above) to build metrics datasets.
There are several metric types and the list is constantly growing to support a wider variety of metrics. As an example of a more complicated metric we could define a metric pulling measures from several data sources as follows:
metric: name: perishables_revenue_per_active_customer description: Revenue from perishable goods (vegetables, fruits, dairy, deli) for each active store. type: ratio type_params: numerator: revenue denominator: active_customers constraints: | product__category in ("vegetables", "fruits", "dairy", "deli")Accessing Metrics#
The Metrics Framework exposes a GraphQL API with a number of clients built on top of that including:
- Command Line Interface (CLI) to pull data locally and improve the dev workflow
- SQL over JDBC to integrate with BI Tools and other SQL Clients
- Python Library to pull metrics into Jupyter or other analytical interfaces
- React Components to build embedded analytics
- Airflow Operators to schedule API requests and pre-construction of metrics
- GraphQL interface underlies all of these is also exposed for the end-user to build their own interfaces
Each of the above APIs follows a common format of pulling metrics in the format of "metrics by dimensions." As a simple example to pull revenue by day in the CLI, the user would write the following request
mql query --metrics revenue --dimensions dsMore can be found in the various APIs docs on more complicated expressions.
Key Concepts#
Metrics as functions - A key concept in the Metrics Frameworks is that metrics are functions that take in various parameters to define the logical operations of the Metrics Framework.
Metrics in the context of dimensions - A metric is enriched in the Metrics Framework using dimensions. Without dimensions, a metric is simply a number for all time and without the context necessary to be useful.
Metrics Interfaces - In order to be a single-source of truth the Metrics Framework must be able to take in any type of modeled data, construct any metric type and serve that metric to the appropriate place. If we can't, then you'd have to define your metrics elsewhere and we would not be accomplishing our product philosophy. Please send us feature requests for new metric types, data modeling approaches, and APIs!
Further Reading#
For further reading on the concepts of the metrics framework please see documentation on:
- Priming: A guide to how the Metrics Framework takes a SQL Query data source and builds a candidate data source similar to a SQL Table data source.
- Query Construction: A guide to how the Metrics Framework takes various candidate Data Sources and resolves an API request into a SQL Query.
- Caching: A guide into the various caching mechanisms that allow the Metrics Framework to resolve queries more efficiently.
FAQ#
- Do my data sets need to be normalized?
- Not at all! While a cleaned and well-modeled data set can be extraordinarily powerful and is the ideal input, you can use any dataset from raw to fully denormalized datasets.
- It's recommended that you apply data consistency and quality transformations such as filtering bad data, normalizing common objects, and data modeling of keys and tables in upstream applications. Transform is most efficient at doing data denormalization, rather than normalization
- If you have not invested in data consistency, that is okay. Transform's Metrics Framework can take SQL queries or expressions to define consistent datasets.
- Why is normalized data the ideal input?
- The Metrics Framework is built to do denormalization efficiently. There are better tools to take raw datasets and accomplish the various tasks required to build data consistency and organized data models. On the other end, by putting in denormalized data you are potentially creating redundancy which is technically challenging to manage and you are reducing the potential granularity that Transform can use to aggregate metrics.
- Why not just make metrics the same as measures?
- One principle of our Metrics Framework is to reduce the duplication of logic sometimes referred to as Don't Repeat Yourself(DRY).
- Many metrics are constructed from reused measures and in some cases constructed from measures from different data sources.
- Additionally, not all metrics are constructed off of measures. As an example, a conversion metric is likely defined as the presence or absence of an event record after some other event record.
- How does the metrics framework handle joins?
- The metrics framework builds joins based on the types of keys and parameters that are passed to identifiers. To better understand how joins are constructed see our documentations on join types.
- Rather than capturing arbitrary join logic, Transform captures the types of each identifier and then helps the user to navigate to appropriate joins. This allows us to avoid the construction of fan out and chasm joins as well as generate legible SQL.
- Are identifiers and join keys the same thing?
- If it helps you to think of identifiers as join keys, that is very reasonable. Identifiers in the Metrics Framework have applications beyond joining two tables, such as acting as a dimension.
- Can a table without a primary or unique identifier have dimensions?
- Yes, but because a dimension is considered an attribute of the primary or unique identifier of the table, they are only useable by the metrics that are defined in that table. They cannot be joined to metrics from other tables. This is common in event logs.